今天给大家分享知乎网站问题及第一条回答内容的采集采集,通过搜索guanjianci采集相应的内容,本案例需要用到抓包工具来获取入口网址,以及获得UA。下面的案例讲解给大家简单作讲解!
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为火车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违法目的或商业用途,我们不对因使用此规则造成的任何法律问题承担责任。
商业版用户有问题或付费定制规则请联系官方客服QQ:800019423 服务热线:400-8757-060 火车采集器V9知乎采集规则分享.rar
火车采集器V9知乎采集规则分享.rar
【案例讲解】
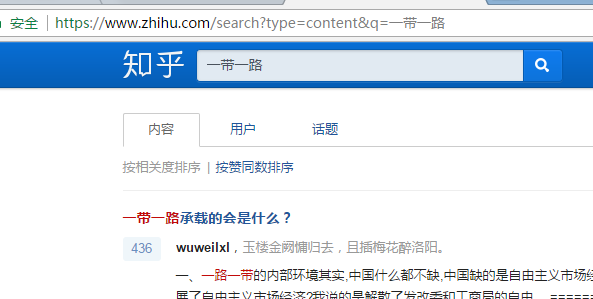
第一步:打开网址 https://www.zhihu.com/ 然后登录账号,然后搜索你想要的guanjianci,如“一带一路”,参照下图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:http://faq.locoy.com/search.html?&keyword=Fiddler 之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照下图: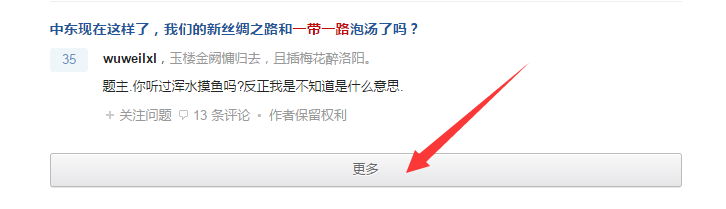
然后回到抓包软件,寻找抓到的网址,参照下图
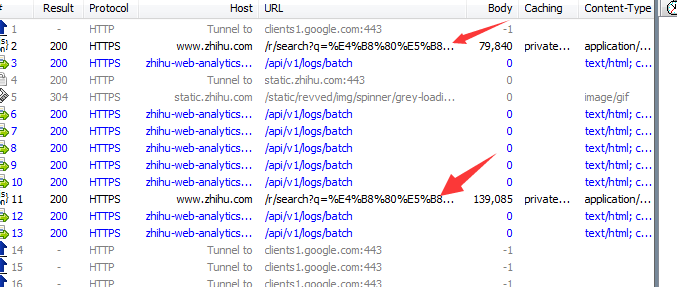
然后通过获取到的网址:https://www.zhihu.com/r/search?q ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们按照这样的规则设置分页参数,这里仅设置5页,如下图:
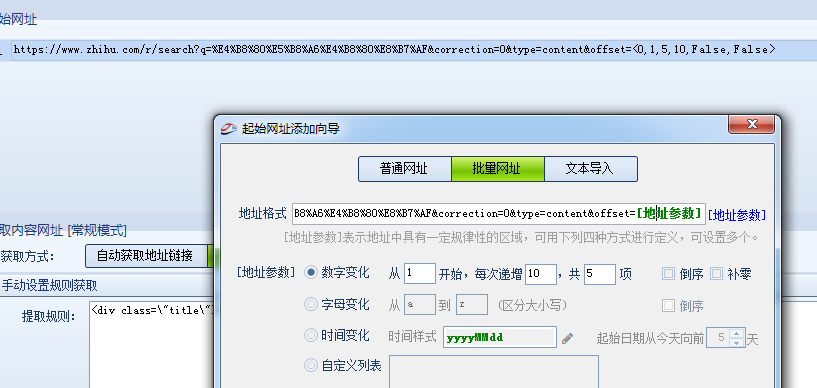
第三步:采集内容网址,通过源码分析,发现网址是这样的“\/question\/49185959\”,如下图:
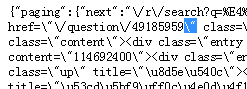
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
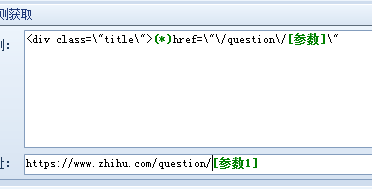
第四步:内容采集设置,在这里要注意的是,知乎需要设置下UA,才能进行采集,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:

先找到内容网址
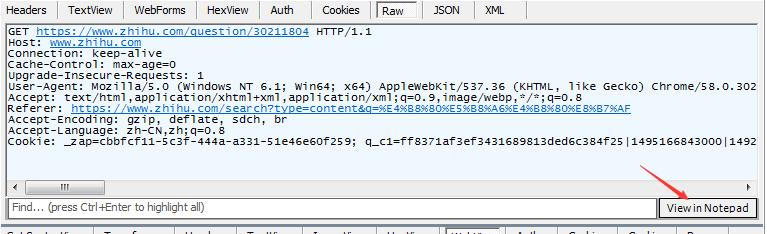
然后右侧点击 RAW 再点击右下解的按钮
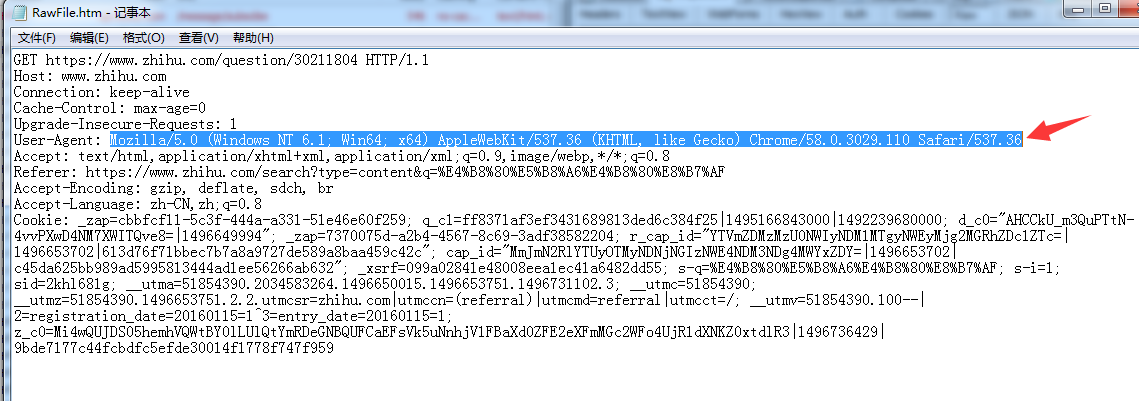
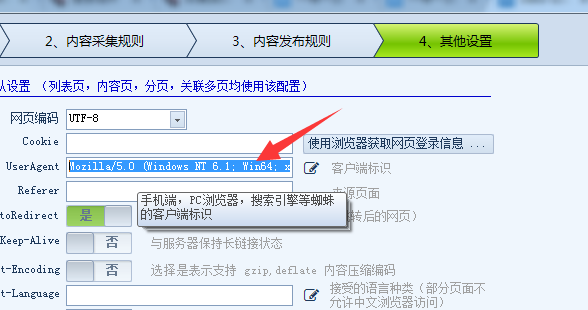
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA里面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有什么特别的难点,就不再细讲,设置好后,进行测试,如下图:
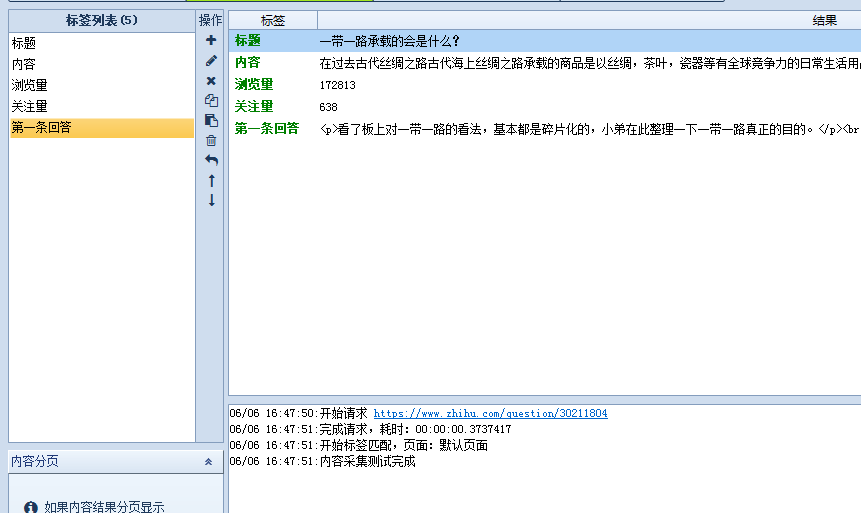
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:400-8757-060
软件购买:http://www.locoy.com/buy